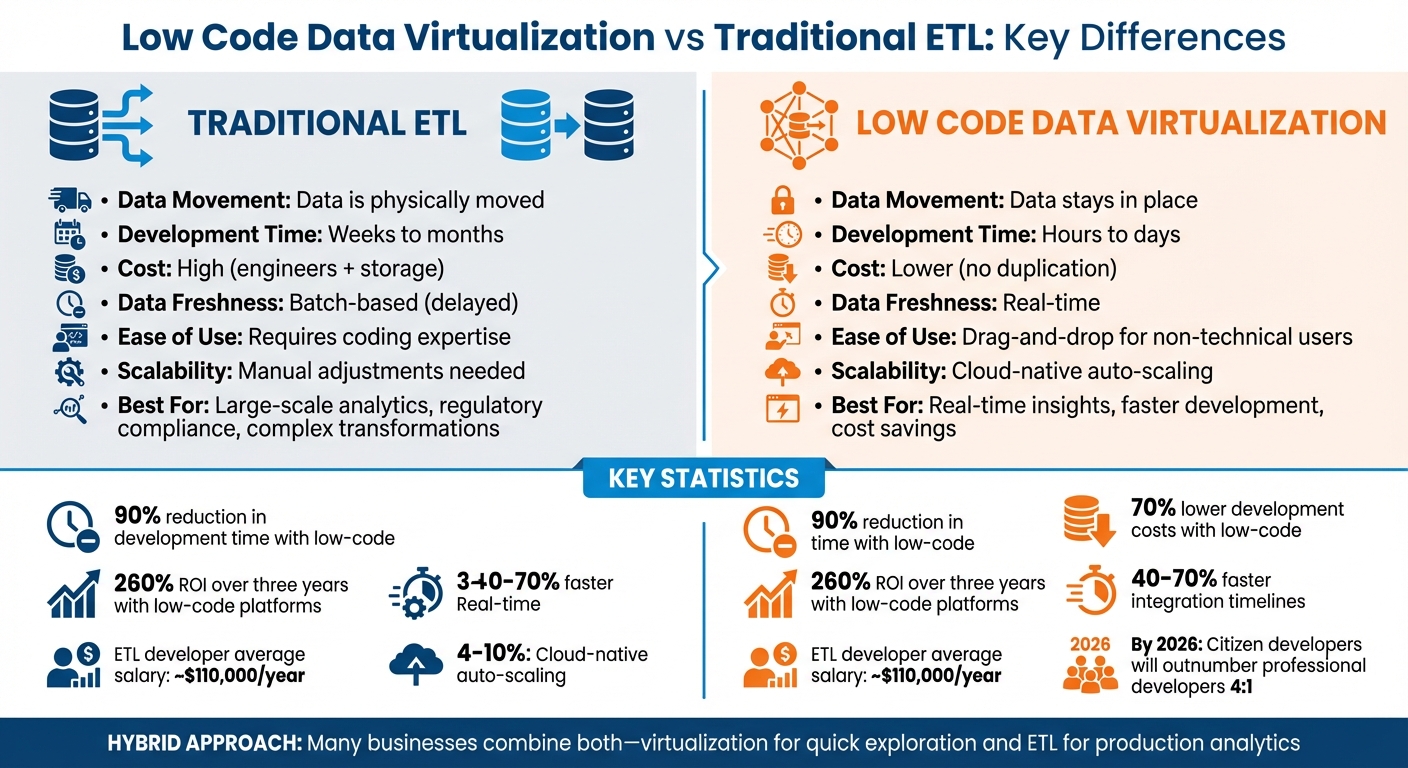
Choosing between low code data virtualization and ETL boils down to your data needs. Here's the key difference: ETL moves and transforms data into a centralized warehouse for historical analysis, while low code data virtualization connects directly to live data sources for real-time access without moving data.
- ETL: Best for large-scale analytics, regulatory compliance, and complex transformations. However, it’s slower, costly, and requires technical expertise. Data is processed in batches, which can lead to delays.
- Low Code Data Virtualization: Ideal for real-time insights, faster development, and cost savings. It simplifies data access but depends on source system performance and struggles with complex analytics.
Quick Comparison
| Feature | ETL | Low Code Data Virtualization |
|---|---|---|
| Data Movement | Data is physically moved | Data stays in place |
| Development Time | Weeks to months | Hours to days |
| Cost | High (engineers + storage) | Lower (no duplication) |
| Data Freshness | Batch-based (delayed) | Real-time |
| Ease of Use | Requires coding expertise | Drag-and-drop for non-technical users |
| Scalability | Manual adjustments needed | Cloud-native auto-scaling |
Summary: Low code data virtualization is faster and more accessible, while ETL is better for handling massive datasets and compliance needs. Many businesses combine both approaches - virtualization for quick exploration and ETL for production analytics.
Low Code Data Virtualization vs Traditional ETL: Key Differences Comparison
Data Integration & Preparation: ETL vs. Data Virtualization
sbb-itb-3a330bb
What is Traditional ETL?
Traditional ETL is a process that gathers data from various sources and consolidates it into a central data warehouse through three main steps: Extract, Transform, and Load. Here’s how it works: data is first extracted from sources like SaaS applications, databases, or APIs. It then moves to a staging area, where it’s cleaned, standardized, and prepared according to specific business rules. Finally, the refined data is loaded into a target data warehouse, ready for analysis.
A defining characteristic of traditional ETL is that it operates in batches. Instead of processing data continuously, it handles large volumes at scheduled intervals - often overnight or during low-traffic hours to minimize the impact on operational systems. Back when storage was expensive, this approach made sense because it allowed data to be processed ahead of time. However, the trade-off is that data freshness is delayed, often measured in hours or even days. This lag can be problematic for businesses needing up-to-the-minute insights.
Another hallmark of traditional ETL is its reliance on data duplication. As data moves through the pipeline - from extraction to staging to final storage - it exists in multiple locations. While this duplication supports compliance needs and preserves historical snapshots, it also drives up storage and infrastructure costs.
Let’s take a closer look at the key features of these systems and the extraction strategies they often use.
Key Features of Traditional ETL
Traditional ETL pipelines are tightly linked to the structure of the data sources they pull from. This means that even small changes, like adding a new field to a source system, can disrupt the entire pipeline. Additionally, all transformation logic is applied before the data ever reaches the warehouse.
When it comes to extracting data, three main strategies are employed:
- Full extraction: Pulling all data from a source.
- Incremental extraction: Collecting only new or updated data.
- Change data capture (CDC): Monitoring and capturing changes in real time.
The focus here is on processing and organizing the data before it’s stored, ensuring control and consistency. However, these features also lead to certain challenges.
Limitations of Traditional ETL
Traditional ETL comes with its fair share of challenges, starting with latency. Because data is processed in batches, it’s often outdated by the time it’s ready for analysis. This delay can hinder timely decision-making, especially in fast-paced environments. Batch processing also creates resource bottlenecks, as large volumes of data are processed at once, requiring substantial infrastructure to handle these peaks.
Another issue is cost. Data duplication across multiple stages - source systems, staging areas, and warehouses - can quickly drive up storage expenses. To save space, raw data is often discarded after transformation. While this reduces storage needs, it also limits flexibility. If new questions arise, the pipeline might need to be rebuilt entirely to retrieve and process the original data again.
Finally, there’s the matter of maintenance. Managing traditional ETL systems requires specialized skills, which can be costly. For example, ETL developers earn an average salary of around $110,000 annually. And with global data generation expected to hit 181 zettabytes by 2025, these batch-oriented systems are increasingly struggling to keep up with the demands of modern data-driven businesses.
What is Low Code Data Virtualization?
Low code data virtualization offers a modern alternative to traditional ETL processes by querying data in real time without physically moving it. It works as a logical layer, creating a unified view of data from various sources - like databases, SaaS apps, APIs, and file systems - while keeping the data at its original location. Instead of extracting, transforming, and loading data into a centralized warehouse, this approach queries the data on demand.
The process relies on query federation. When a user makes a request, the platform splits it into sub-queries tailored to each source, runs them simultaneously on the original systems, and combines the results in real time. This ensures access to up-to-date data, which is critical for applications like fraud detection or real-time inventory tracking.
leading low code and no code platforms simplify the process by reducing the need for extensive coding. With features like drag-and-drop interfaces, metadata catalogs, and point-and-click tools, even business analysts and non-technical users can explore data and create virtual views without needing to write complex SQL or backend code. According to Gartner, citizen developers are expected to outnumber professional developers by 4:1 by 2026.
By leaving data where it resides, organizations can avoid duplication, leading to lower infrastructure costs, reduced storage needs, and fewer cloud data egress charges. This logical integration approach can cut integration timelines and maintenance efforts by 40% to 70% compared to traditional ETL-heavy methods.
Key Features of Low Code Data Virtualization
Low code data virtualization provides real-time data access through a visual interface equipped with pre-built connectors and drag-and-drop tools, enabling rapid development. Unlike ETL, which operates in batches, this method processes queries on demand, ensuring users always access the most current data. Some organizations report up to a 90% reduction in development time, turning months of work into weeks.
Another advantage is minimal data duplication. Since data stays at the source, there’s no need for staging areas or redundant storage, cutting costs and simplifying compliance by maintaining a single source of truth.
Security and governance are also centralized. Virtualization platforms enforce policies at the virtual layer, applying consistent controls across all connected data sources. Features like data masking, access controls, and audit trails can be managed centrally, even when dealing with diverse systems.
Limitations of Low Code Data Virtualization
While low code data virtualization has its strengths, it’s not without challenges. Performance can be a concern. Because it queries source systems in real time, its efficiency depends heavily on the processing power and network conditions of those systems. If a production database is already under heavy load, adding virtualization queries can slow down operations for other users.
Handling highly complex analytics is another hurdle. Joining large tables or processing massive datasets in real time can strain source systems, leading to delays. In such cases, pre-aggregated data stored in a warehouse may perform better for analytical tasks.
There’s also the impact on source systems to consider. Virtualization relies on operational databases, so poorly optimized queries or high query volumes can disrupt business-critical processes. Caching frequently accessed queries can help, but it requires careful setup and monitoring.
Lastly, while low-code interfaces make data access easier, they can’t handle every scenario. Advanced transformations or custom business logic may still require traditional coding, limiting the "no-code" promise in more complex use cases.
The next section will explore how these approaches compare in terms of efficiency, scalability, and usability.
Efficiency, Scalability, and Ease of Use Comparison
When comparing traditional ETL and low-code data virtualization, the differences become clear across three critical areas: data freshness, scalability, and ease of use.
Traditional ETL relies on batch processing, which means your data is only as current as the last time it was loaded. This delay can be a challenge for use cases that demand up-to-the-minute accuracy, like fraud detection or tracking inventory. On the other hand, low-code data virtualization queries data directly in real time, making it ideal for scenarios where immediate access to live data is essential. However, for large-scale analytics, traditional ETL can shine due to its pre-integrated, optimized datasets (e.g., through columnar storage or indexing), which can speed up queries on massive datasets.
Scalability: Traditional vs. Low-Code
Scaling with traditional ETL often involves partitioning data and adding compute nodes, such as Spark clusters. While effective, this method requires skilled engineers to manage and fine-tune the infrastructure. In contrast, low-code platforms offer cloud-native auto-scaling, which automatically adjusts resources during spikes in demand. For example, AT&T saved $2 million annually in work hours by automating integrations with MuleSoft, while Roche increased its data release frequency from quarterly to over 120 times per month using low-code automation.
Ease of Use: A Game Changer
Ease of use is where low-code tools truly stand apart. Traditional ETL workflows require extensive programming expertise, often leading to project backlogs of six to eight months. Low-code platforms simplify the process with drag-and-drop interfaces, cutting coding requirements by up to 75%. A FinTech startup, for instance, transitioned its daily transaction workflows to QuantumDataLytica's no-code environment in 2025, slashing coding tasks by 75% and eliminating the need for dedicated data engineering staff. Low-code tools have reduced development timelines by as much as 90%, turning months-long projects into tasks completed in just days.
This reduced technical barrier also impacts workforce planning. Gartner predicts that by 2026, citizen developers will outnumber professional developers by 4:1, with 41% of organizations already enabling business analysts to build solutions using low-code tools. This shift not only saves time but also significantly lowers costs, with low-code implementations cutting development expenses by up to 70% and ongoing support costs by approximately 60%. Still, for highly complex systems, traditional ETL may offer greater precision and the ability to fine-tune performance, which visual interfaces might not fully replicate.
Comparison Table: Efficiency, Scalability, and Ease of Use
| Feature | Traditional ETL | Low-Code Data Virtualization |
|---|---|---|
| Data Movement | High; data is physically extracted and loaded | Minimal; data is queried in place |
| Development Speed | Slow; weeks to months of manual scripting | Rapid; hours to days with visual interfaces |
| Cost Efficiency | High labor costs for specialized engineers | Pay-as-you-go model with up to 70% lower costs |
| User-Friendliness | Low; requires programming expertise | High; drag-and-drop interfaces for non-technical users |
| Scalability | Manual cluster management, limited at large scales | Cloud-native auto-scaling adjusts dynamically |
| Data Freshness | Batch-based; reflects last load cycle | Real-time; queries live source data |
Each approach has its strengths and limitations, but low-code data virtualization offers clear advantages in speed, accessibility, and cost savings, while traditional ETL remains a strong choice for highly complex, large-scale analytics.
Advantages and Disadvantages of Each Approach
Taking a closer look at the operational differences discussed earlier, let's break down the strengths and limitations of both approaches.
Both traditional ETL and low-code data virtualization bring distinct benefits to the table, but they also come with trade-offs that can influence your data strategy.
Traditional ETL is a reliable choice for handling large-scale historical analytics. By extracting, transforming, and loading data into warehouses designed for analytical tasks, it enables fast, complex queries and ensures immutable snapshots - key for meeting regulatory and auditing requirements. However, this approach can be time-consuming, with development cycles often stretching into weeks or months due to manual scripting. Maintenance can also be costly, especially since ETL developer salaries average about $109,881 annually. Even small schema changes or the addition of new data sources may require rebuilding pipelines, adding to the workload.
On the other hand, low-code data virtualization shines in terms of speed and cost-effectiveness. It allows for quick prototyping by creating or adjusting virtual views in just hours, eliminating the need for data movement or physical schema modifications. Development costs can be reduced by up to 70%, and support expenses by up to 60%. That said, its performance depends heavily on the ability of source systems to handle real-time queries. This can pose challenges for high-volume historical analytics or complex joins. Additionally, embedding business logic in proprietary formats can lead to vendor lock-in, which is a concern for long-term flexibility.
The decision ultimately depends on your priorities: speed and flexibility favor low-code data virtualization, while performance and stability lean toward traditional ETL. Many modern data teams are opting for a hybrid approach, leveraging virtualization for quick discovery and ETL for critical production workloads. Below is a side-by-side comparison of the pros and cons of each method.
Comparison Table: Pros and Cons
| Approach | Advantages | Disadvantages |
|---|---|---|
| Traditional ETL | • High performance for complex analytics • Optimized for large-scale batch processing • Immutable snapshots for compliance |
• Slow development cycles • High labor costs (e.g., ~$109,881/year) • Rigid structure requiring extensive pipeline rebuilds |
| Low-Code Data Virtualization | • Real-time data access • Up to 90% faster development • Up to 70% lower development costs • Empowers citizen developers • Zero data movement |
• Performance reliant on source systems • Limited for high-volume historical queries • Risk of vendor lock-in , a topic often explored in market research on top platforms • May struggle with highly complex transformations |
When to Choose Low Code Data Virtualization Over Traditional ETL
Deciding between low-code data virtualization and traditional ETL boils down to your organization's specific needs. The key factors are how up-to-date your data needs to be, the size of your datasets, and who will be building and maintaining the solution.
Low-code data virtualization is ideal for scenarios where real-time insights are critical. For example, monitoring retail inventory, detecting fraud in financial transactions, or tracking production metrics on a factory floor all benefit from this approach. If your business relies on current data rather than historical summaries, virtualization is the way to go. It's also a great option when you’re experimenting with new data sources. Many organizations report 40–70% faster integration timelines using low-code data virtualization.
On the other hand, traditional ETL shines when handling massive datasets that require intricate transformations or when regulatory compliance demands detailed historical records. If your analysts are running complex queries involving millions of rows or you need immutable audit trails for financial reporting, ETL's pre-optimized storage ensures these processes run efficiently.
Many businesses find that a hybrid approach offers the best of both worlds. Low-code data virtualization is excellent for quick prototyping and validating use cases, while traditional ETL provides the stability and performance needed for large-scale production analytics. This combination allows you to adapt quickly without overcommitting to infrastructure costs. A common strategy is to use virtualization for discovery and ETL for production. Start with top low-code platforms to experiment and prove value, then transition high-volume workloads to ETL when they're ready for production. This balance lets you innovate while ensuring reliable analytics for critical operations.
Decision Table: Choosing the Right Approach
| Requirement | Low-Code Data Virtualization | Traditional ETL |
|---|---|---|
| Data Velocity | Real-time or near real-time insights needed | Batch processing (hourly, daily) |
| Data Volume | Low to moderate (source systems handle queries) | Massive datasets needing pre-aggregation |
| Transformation Complexity | Simple to moderate (handled dynamically) | Complex, multi-step logic |
| Historical Context | Current state focus, limited history | Deep audit trails, point-in-time snapshots |
| Business Need | Operational dashboards, rapid exploration | Regulatory reporting, financial compliance |
| User Type | Analysts and citizen developers | Data engineers and architects |
| Infrastructure Budget | Lower (no data duplication or storage costs) | Higher (requires dedicated storage) |
Conclusion
Deciding between low-code data virtualization and traditional ETL isn't about picking one over the other - it’s about aligning the right tool with your business needs. Data virtualization is ideal for real-time insights, quick prototyping, and experimenting with new data sources without hefty infrastructure costs. On the other hand, traditional ETL is the go-to for handling complex transformations, large-scale datasets, and ensuring compliance with strict regulatory requirements that demand unchangeable audit trails.
The numbers tell a compelling story. Companies using low-code and no-code platforms report up to 90% faster development times and see a 260% return on investment over three years. At the same time, 68% of organizations identify traditional ETL's complexity as a major hurdle in advancing their data strategies. These insights explain why many forward-thinking businesses are adopting hybrid models - leveraging virtualization for discovery and operational dashboards while continuing to rely on ETL pipelines for robust, production-ready analytics. This combination allows them to harness the strengths of both approaches.
As Promethium aptly puts it:
"Data virtualization isn't replacing ETL or data warehouses - it's solving different problems."
The shift toward democratizing data integration is transforming the landscape. Gartner projects that by 2026, citizen developers will outnumber professional developers by a ratio of 4:1. This evolution empowers business analysts to create solutions independently, freeing up expert ETL teams to focus on more intricate, high-impact projects.
FAQs
How do I decide between ETL and data virtualization?
Choosing between ETL and data virtualization comes down to what your data goals are. ETL works best when you need to handle large-scale data migrations, create consistent historical reports, or consolidate data into a single, centralized location. On the other hand, data virtualization shines when you need instant access to live data without copying it, making it perfect for real-time queries and fast, flexible analysis. Many businesses combine both approaches to get the benefits of structured storage alongside real-time data access.
Will data virtualization slow down my source systems?
Data virtualization usually avoids slowing down source systems because it works by accessing data in real time without the need to move or copy it. This approach contrasts with traditional ETL processes, which can add processing strain. By querying data where it already exists, it reduces the load on source systems. That said, extremely complex or frequent queries might cause some performance issues. However, most setups rely on lightweight connections and fine-tuned queries to keep any potential impact minimal.
What does a hybrid ETL + virtualization setup look like?
A hybrid ETL and virtualization approach brings together the strengths of both methods: traditional ETL processes handle the heavy lifting of processing and storing historical data, while data virtualization provides real-time access to distributed sources. ETL focuses on batch processing, ensuring data consistency and reliability, while virtualization allows for quick querying without the need to physically move data.
This combination offers several advantages. It minimizes data duplication, cuts down on storage costs, and supports more adaptable and scalable data architectures. Whether you're working on historical reporting or need real-time insights for decision-making, this setup provides the flexibility to handle both seamlessly.


